2021年暑期夏令营笔记(day6)
0x00 基础知识
缓冲区溢出
内存的分类标准——五分类
在C++中,内存分成5个区,他们分别是堆,栈,自由存储区,全局/静态存续区,常量存续区。
(1)**栈:**内存由编译器在需要时自动分配和释放。通常用来存储局部变量和函数参数,函数调用后返回的地址。(为运行函数而分配的局部变量、函数参数、函数调用后返回地址等存放在栈区)。栈运算分配内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
(2)**堆:**内存使用new进行分配,使用delete或delete[]释放。如果未能对内存进行正确的释放,会造成内存泄漏。但在程序结束时,会由操作系统自动回收。
(3)自由存储区:使用malloc进行分配,使用free进行回收。
(4)全局**/**静态存储区:全局变量和静态变量被分配到同一块内存中,C语言中区分初始化和未初始化的,C++中不再区分了。(全局变量、静态数据 存放在全局数据区)
(5)常量存储区:存储常量,不允许被修改。
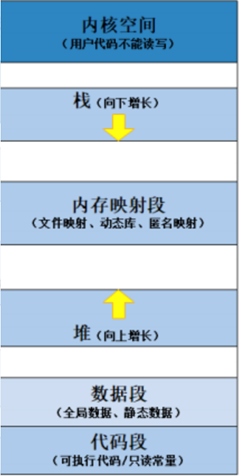
内存的分类标准——另一种五分类
(1)栈又叫堆栈,非静态局部变量/函数参数/返回值等等 ,还有每次调用函数时保存的信息。每当调用一个函数时,返回到的地址和关于调用者环境的某些信息的地址,比如一些机器寄存器,就会被保存在栈中。然后,新调用的函数在栈上分配空间,用于自动和临时变量。
2.内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。
3.堆用于程序运行时动态内存分配,堆是可以上增长的。堆区域从BSS段的末尾开始,并从那里逐渐增加到更大的地址。堆是由程序员自己分配的。堆区域由所有共享库和进程中动态加载的模块共享。
4.数据段分为初始化数据段和未初始化数据段。初始化的数据段,通常称为数据段,是程序的虚拟地址空间的一部分,它包含有程序员初始化的全局变量和静态变量,可以进一步划分为只读区域和读写区域。未初始化的数据段,通常称为bss段,这个段的数据在程序开始之前有内核初始化为0,包含所有初始化为0和没有显示初始化的全局变量和静态变量。
5.代码段也叫文本段,是对象文件或内存中程序的一部分,其中包含可执行代码和只读常量。文本段在堆栈的下面,是防止堆栈溢出覆盖它。,通常代码段是共享的,对于经常执行的程序,只有一个副本需要存储在内存中,代码段是只读的,以防止程序以外修改指令。
内存的分类标准——三分类
(1)静态(全局)存储区**——**static:内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。它主要存放静态数据、全局数据和常量。也是程序结束后,由操作系统释放。
(2)栈区**——**stack:在执行函数时,函数参数,局部变量(包括const局部变量),函数调用后返回的地址都在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
(3)堆区——heap:亦称动态内存分配。程序在运行的时候用malloc或new申请任意大小的内存,程序员自己负责在适当的时候用free或 delete释放内存。动态内存的生存期可以由我们决定,如果我们不释放内存,程序将在最后才释放掉动态内存。 但是,良好的编程习惯是:如果某动态内存不再使用,需要将其释放掉,否则,我们认为发生了内存泄漏现象。
内存的分类标准——四分类
(1)代码区-–-—-主要存储程序代码指令,define定义的常量。
(2)全局数据区-–-–主要存储全局变量(常量),静态变量(常量),常量字符串。
(3)栈区-–-—-主要存储局部变量,栈区上的内容只在函数范围内存在,当函数运行结束,这些内容也会自动被销毁。其特点是效率高,但内存大小有限。
(4)堆区-–-—-由malloc,calloc分配的内存区域,其生命周期由free决定。堆的内存大小是由程序员分配的,理论上可以占据系统中的所有内存。

栈是机器系统提供的数据结构 , 而堆则是C/C++函数库提供的 。对子程序的调用就是直接利用栈完成的 。
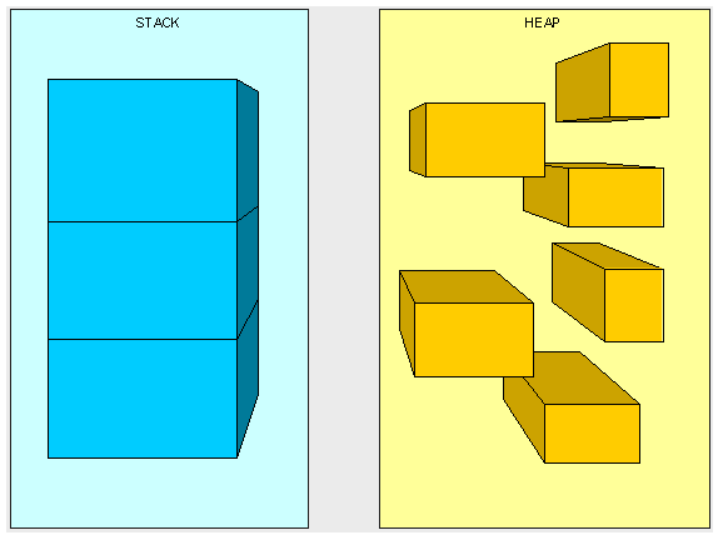
栈内存:由高地址向低地址,连续,快速,空间小;
堆内存:由低地址向高地址,不连续,缓慢,空间大。
| 栈区 |
| Stack memory内存空间由操作系统自动分配和释放。 |
| Stack Memory内存空间有限。 |
栈和堆中主要放置了四种类型的数据:值类型(Value Type),引用类型(Reference Type),指针(Pointer),指令(Instruction)。
值类型:bool、byte、char、decimal、double、enum、float、int、long、sbyte、short、struct、uint、ulong、ushort
引用类型:class、interface、delegate、object、string引用类型总放在堆中,值类型和指针总放在他们被声明的地方。
函数调用约定参数传递顺序:
1.从右到左依次入栈:__stdcall,__cdecl,__thiscall,__fastcall
2.从左到右依次入栈:__pascal
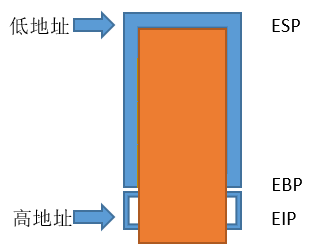
栈的布局

Windows平台安全防护机制:
- GS编译技术
- SEH的安全校验机制
- Heap Cookie,Safe Unlinking等一系列堆安全机制
- DEP数据执行保护
- ASLR加载地址随机
- SEHOP SEH的覆盖保护
Linux平台安全防护机制:
- NX: No-Execute,类似windows的DEP数据执行保护,将数据所在内存页标志为不可执行;
- ****Canary:类似windows的GS,在栈底附近放置随机cookie,函数返回时判断cookie是否被改变;
- PIE:地址空间分布随机化,程序入口基址每次加载均随机变化,类似windows的ASLR。
.PLT表—函数调用CALL时先跳转到函数的PLT地址,地址中存放的是.GOT表地址。
.GOT表—用于加载动态链接时,间接寻址得到函数的真实地址,函数真实地址在函数调用时才会写入GOT表。
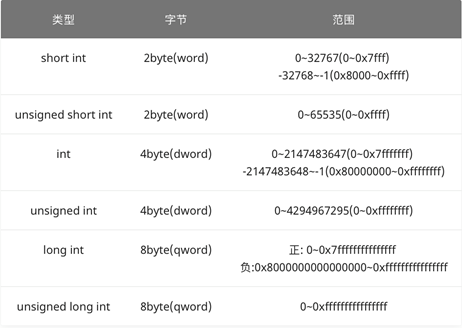
八个比特(Bit)称为一个字节(Byte),两个字节称为一个字(Word),两个字称为一个双字(Dword),两个双字称为一个四字(Qword)。
0x01 2017“红帽杯”pwn1
1、分析程序流程,运行程序发现流程非常简单,即输入,原样输出。

2、IDA静态分析,scanf(“%s”,地址),未对输入做限制,直接输入bad data覆盖返回地址即可。
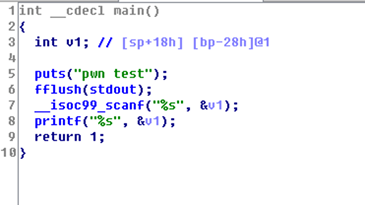
3、GDB调试,padding=0x28,要是4的倍数所以为52,生成大于56个字符,即可覆盖返回地址。
![]()
4、检查安全防护机制 ,使用checksec发现,开启了NX。
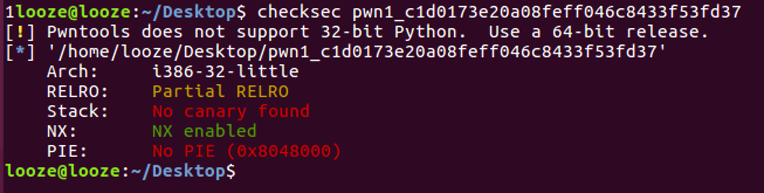
5、思路,通过scanf函数读取’/bin/sh\x0’保存到.bss段,采用ROP链(pop xxx; pop xxx; ret;指令)来跳过scanf函数的两个参数,接着返回到system函数地址执行.bss段上的’/bin/sh\x0’,达到getshell目的。我们需要知道scanf函数地址、.bss段基址、ROP链地址、system函数地址、格式化串%s地址(scanf函数需要)
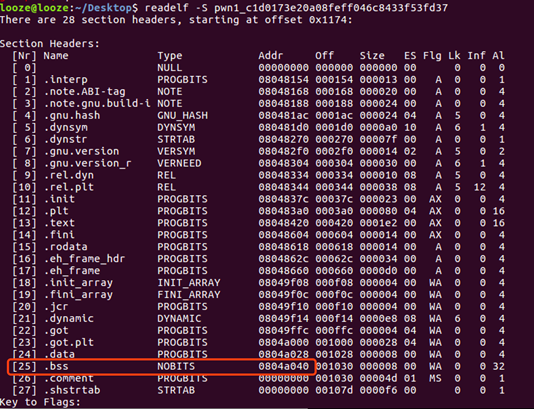
6、构建EXP,在程序.plt段找到system和scanf的PLT地址。
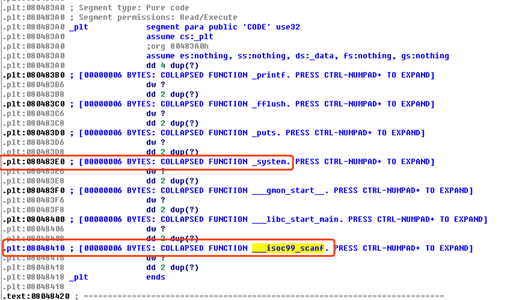
通过readelf –S xxx找到.bss段基址
通过IDA,在.rodata段找到格式化串地址
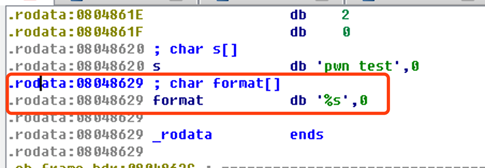
通过ROPgadget找到ROP链, ROPgadget --binary 'PATH' --only "pop|pop|ret"
0x02 gdb/pwndbg 常用命令
参考自https://www.cnblogs.com/zhwer/p/12494317.html
*为可选 黑色 为gdb原生命令 绿色 为 pwndbg 或 peda 插件命令
| 命令 | 缩写 | 效果 |
|---|---|---|
| gdb |
添加新程序 | |
| gdb attach |
负载运行的程序 | |
| set args <*argv> | 设置程序运行参数 | |
| show args | 查看设置好的运行参数 | |
| quit | q | 退出gdb |
| symbol |
sy | 导入符号表 |
| info <*b> | i | 查看程序的状态/*查看断点 |
| frame | f | 查看栈帧 |
| backtrace | bt | 查看堆栈情况 |
| list | l | 显示源代码 (debug模式) |
| display | disp | 跟踪查看某个变量 |
| start | s | 启动程序并中断在入口 debug模式停在main(),否则停在start() |
| run | r | 直接运行程序直到断点 |
| continue | c | 暂停后继续执行程序 |
| next | n | 单步步过 |
| step | s | 单步步入,函数跟踪 |
| finish | fin | 跳出,执行到函数返回处 |
| break /* |
b | 下断点 |
| watch | 下内存断点并监视内存情况 | |
| p | 打印符号信息(debug模式) | |
| i r a | 查看所有寄存器 | |
| i r <esp/ebp..> | 查看某个寄存器 | |
| set $esp = 0x01 | 修改某个寄存器的值 | |
| heap | 查看分配的chunk | |
| vmmap | 查看内存分配情况 | |
| bin | 查看 Bin 情况 | |
| x / |
显示内存信息,具体用法附在下面 | |
| context | 打印 pwnbdg 页面信息 | |
| dps |
优雅地显示内存信息 | |
| disassemble |
打印函数信息 | |
| vmmap | 显示程序内存结构 | |
| search <*argv> | 搜索内存中的值 输入 search -h 可查询用法 | |
| checksec | 查看程序保护机制 | |
| parseheap | 优雅地查看分配的chunk | |
| aslr <on/off> | 打开/关闭 ASLR 保护 | |
| pshow | 显示各种踏板选项和其他设置 | |
| dumpargs |
显示在调用指令处停止时传递给函数的参数 | |
| dumprop |
显示特定内存范围内的所有ROP gadgets | |
| elfheader | 从调试的elf文件获取头信息 | |
| elfsymbol | 从ELF文件获取非调试符号信息 | |
| procinfo | 显示来自/proc/pid的各种信息 | |
| readelf | 从elf文件获取头信息 |
x指令的具体用法:n、f、u为控制打印形式的参数
’num’ 表示打印的数量
’n’ 代表打印格式,可为o(八进制),x(十六进制),d(十进制),u(无符号十进制),t(二进制),f(浮点类型),a(地址类型),i(解析成命令并反编译),c(字符)和s(字符串)
‘f’ 用来设定输出长度,b(byte),h(halfword),w(word),giant(8bytes)。
‘u’ 指定单位内存单元的字节数(默认为dword) 可用b(byte),h(halfword),w(word),giant(8bytes)替代
x指令也可以显示地址上的指令信息,用法:x/i
0x03 堆溢出
堆管理器处于用户程序与内核中间,主要负责响应用户的申请内存请求和管理用户释放的内存。
为了保持内存管理的高效性,内核一般都会预先分配很大的一块连续的内存,然后让堆管理器通过某种算法管理这块内存。只有当出现了堆空间不足的情况,堆管理器才会再次与操作系统进行交互。
用户释放的内存并不是直接返还给操作系统的,而是由堆管理器进行管理。这些释放的内存可以来响应用户新申请的内存的请求。
linux glibc使用的ptmalloc2实现原理
宏观角度:创建堆、堆初始化、删除堆
微观角度:申请内存块、释放内存块
堆内存申请和释放实际是调用sbrk和mmap实现的。
ptmalloc 中使用一个 chunk 来表示用户请求分配的空间,释放后并非立即归还给操作系统。它们会被表示为一个chunk(堆分配最小单元),共分为4类(allocated chunk、free chunk、top chunk、Last remainder chunk),ptmalloc使用空闲管理链表来管理这些空闲的数据结构。fd 、bk字段只有在空闲chunk中存在,表示双向链表的前向指针和向后指针,否则表示用户数据。
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
typedef struct malloc_chunk* mchunkptr;fd_nextsize, bk_nextsize,也是只有 chunk 空闲的时候才使用,不过其用于较大的 chunk(large chunk)。fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适 chunk 时挨个遍历。
//malloc.c
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
。。。。。。
};
typedef struct malloc_chunk* mchunkptr;prev_size**,如果该 chunk 的物理相邻的前一地址** chunk**(**两个指针的地址差值为前一 chunk **大小)**是空闲的话,那该字段记录的是前一个 chunk 的大小 (包括 chunk 头)。否则,该字段可以用来存储物理相邻的前一个 chunk 的数据。这里的前一 chunk 指的是较低地址的 chunk 。
size,该 chunk 的大小,大小必须是 2 * SIZE_SZ 的整数倍。如果申请的内存大小不是 2 * SIZE_SZ 的整数倍,会被转换满足大小的最小的 2 * SIZE_SZ 的倍数。 32 位系统中,SIZE_SZ 是 4;64 位系统中,SIZE_SZ 是 8。
**注意:**size_t 在 64 位中是 64 位无符号整数,32 位中是 32 位无符号整数。
已分配的chunk
chunk 处于分配状态时,从 fd 字段开始是用户的数据。
mem指针:指向用户申请空间首地址,申请成功后返回给用户。

size字段的低三位从高到低(AMP)各有不同含义,不影响chunk 的大小。
(A) NON_MAIN_ARENA:标识chunk 是否不属于主线程,1 表示不属于,0 表示属于;
(M) IS_MAPPED:记录当前 chunk 是否是由 mmap 分配的。;
(P) PREV_INUSE,记录前一个 chunk 是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的 P 位都会被设置为 1,以便于防止访问前面的非法内存。当P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲 chunk 之间的合并。
空闲的chunk
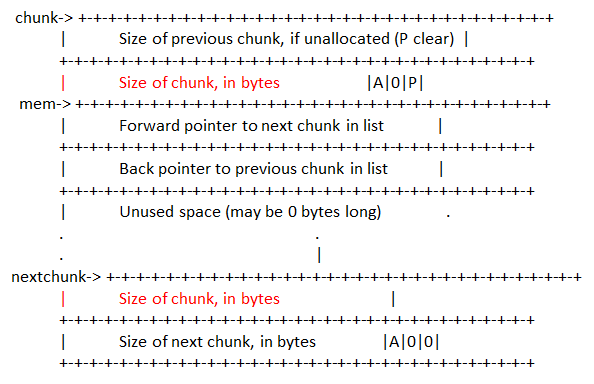
chunk处于空闲****状态时,会被添加到对应的空闲管理链表中,有两个位置记录其相应的大小。
fd字段指向下一个(非物理相邻)空闲的 chunk;bk 字段指向上一个(非物理相邻)空闲的 chunk。
通过 fd 和 bk 可以将空闲的 chunk 块加入到空闲的 chunk 块链表进行统一管理。
bin的概念
bin是一系列链表,用于系统在分配时寻找哪一个chunk是最适合的。
bin共有四种类型:fastbin、small bin、large bin和unsorted bin。
fastbin
Fastbin是chunk最小的,也是分配起来最快的,因而得名fast bin.它可以分配的chunk的范围从0到80字节,总共有10个链表,分别对应不同的大小(在初始化的时候其实只设置到64字节,而不是80字节), Fastbin链表中的chunk实际上没有使用chunk结构体中的bk指针,所以这个chunk链表就成为了单链表,使得操作更加迅速,另外,fastbin的chunk无法进行合并,所以指明前一个chunk是否被使用的标志为永远为1。
small bin
存储512字节以内的chunk。bin共62个,每一个bin的大小间距是8个字节,如果有两个相邻chunk都为空闲则需要合并,其中每一个bin的大小是固定的(也就是确定的,主要和large bin作比较)。
large bin
包含大于等于512字节的chunk。Bin共63个,组织方法如下:
32个bin 每64个字节一个阶层,比如第一个512-568字节,第二个576 - 632字节……
16个bin 每512字节一个阶层
8个bin每4096字节一个阶层
4个bin每32768字节一个阶层
2个bin每262144字节一个阶层
最后一个bin包括所有剩下的大小
和small bin不同的地方在于,这里的每一个bin都保存的是一个范围而不是一个确定的值,每一个bin内的chunk大小是排好序的。不过和small bin一样也可以合并。
unsorted bin
当small或者large chunk(即small bin和large bin当中的chunk)被释放的时候会放入这个bin当中,这个bin只有一个,是一个循环链表,任意大小的chunk都可以放入这个bin。
top chunk 和 last remainder
Top chunk其实是有效内存的一个边界,用来处理bin中的chunk没有可用chunk的情况。是要来保证分配成功的最后一条防线,他的格式和其他chunk一样,不过他的位置在有效内存的最边上(这就是为什么说他作为有效内存的边界),而且他的前一个被使用的flag标志一直都被设置,防止访问前一个内存,在glibc的代码中认为这个chunk永远存在,当他的大小不够的时候会从系统中通过系统调用来分配新的内存,通过brk分配的内存会直接加入top chunk,通过mmap分配的内存会拥有新的heap,当然也拥有了新的top chunk. 在top chunk当中分配,是通过把top chunk切成两半,一半被分配走,另外一半成为新的top chunk,同时也成为了last remainder。
Tcache
Tcache全名为Thread Local Caching,它为每个线程创建一个缓存,里面包含了一些小堆块。每个线程默认使用64个单链表结构的bins,每个bins最多存放7个chunk,64位机器16字节递增,从0x20到0x410,也就是说位于以上大小的chunk释放后都会先行存入到tcache bin中。对于每个tcache bin单链表,它和fast bin一样都是先进后出,而且prev_inuse标记位都不会被清除,所以tcache bin中的chunk不会被合并,即使和Top chunk相邻。
相对于其余四种bin,tcache是出现的最晚的,在libc2-26中才加入。
UAF漏洞
Use After Free 指当一个内存块被释放之后再次被使用。
会出现以下几种情况:
1)内存块被释放后,对应指针设置为 NULL , 再次使用,程序崩溃。
2)内存块被释放后,对应指针没有设置为 NULL ,在它下一次被使用之前,没有代码对这块内存块进行修改,那么程序很有可能可以正常运转。
3)内存块被释放后,对应指针没有设置为 NULL,下一次使用之前,有代码对这块内存进行了修改,当程序再次使用这块内存时,就很有可能会出现奇怪的问题。
而我们一般所指的 Use After Free 漏洞主要是后两种。此外,我们一般称被释放后没有被设置为 NULL 的内存指针为悬空指针(dangling pointer)。
#include <stdio.h>
#include <stdlib.h>
//定义结构体test
typedef struct test
{
char *mytest;
void (*func)(char *str);
} TEST;
//定义函数myfunc1
void myfunc1(char *str)
{
printf("%s\n", str);
}
//定义函数myfunc2
void myfunc2()
{
printf("print my function2\n");
}
int main()
{
TEST *t; //动态申请内存
t = (TEST *)malloc(sizeof(struct test));
t->func = myfunc1;
t->mytest = "my struct test";
t->func("my struct func");
//释放指针t
free(t);
t->func("Emm ? I can use it after free !");
//再次使用释放后的指针t
t->func = myfunc2;
t->func("Anything");
//指针t设置为NULL
t = NULL;
printf("After set the point to NULL");
t->func(“Anything”);//调用产生段错误
return 0;
}Double Free
free函数在释放堆块时,会通过隐式链表判断相邻前、后堆块是否为空闲堆块;如果堆块为空闲就会进行合并,然后利用Unlink机制将该空闲堆块从Unsorted bin中取下。如果用户精心构造的假堆块被Unlink,很容易导致一次固定地址写,然后转换为任意地址读写,从而控制程序的执行。
PS: libc 2.27开始tcahce严格检查,但是还是有办法实现double free。
unlink 宏中主要的操作如下:
FD = P->fd; //获取显式链表中前一个块 FD
BK = P->bk; //获取显示链表中后一个块 BK
FD->bk = BK; //设置FD的后一个块
BK->fd = FD; //设置BK的前一个块
//由于unlink的危险性,添加了一些检测机制,
FD = P->fd;
BK = P->bk;
if (__builtin_expect (FD->bk != P || BK->fd != P, 0))
malloc_printerr (check_action, “corrupted double-linked list”, P, AV);
0x04 单字节溢出&整数溢出
单字节溢出(off-by-one )是指单字节缓冲区溢出,这种漏洞的产生往往与边界验证不严和字符串操作有关,当然也不排除写入的 size 正好就只多了一个字节的情况。
需要说明的一点是 off-by-one 是可以基于各种缓冲区的,比如栈、堆、bss 段等。
边界验证不严通常包括:
1)使用循环语句向堆块中写入数据时,循环的次数设置错误(这在 C 语言初学者中很常见)导致多写入了一个字节。
2)字符串操作不合适,如strcpy()。
由于整数在内存里面保存在一个固定长度的空间内,它能存储的最大值和最小值是固定的,如果我们尝试去存储一个数,而这个数又大于这个固定的最大值时,就会导致整数溢出。(x86-32 的数据模型是 ILP32,即整数(Int)、长整数(Long)和指针(Pointer)都是 32 位。)